Neural Networks and How do Machines Learn Meaning 15 Jan 2019
How are you going to teach a kid to recognize objects? To teach them what a car is, for example, you may show them multiple images of different cars, you may show them real cars on the road or toy cars, and you may repeat the word “car” over and over as you do. While they are observing the common pattern between the different images of cars we are showing them, the kid will learn to associate the label “car” with the object.
But how do computers learn? Humans learn by association and repetition, while machines consist of on/off switches for processing meaningless symbols. So, how can we make computers understand the meaning of words, how can we guide them to create association rules, and how can we help them learn the meaning of actions and documents?
Artificial intelligence is helping machines to learn in a similar way as humans do. Using “deep learning,” AI-powered machines are trying to mimic the human brain, in the sense that some concepts can be taught by repeatedly associating the same label “car” to a set of objects that have the same qualities, like 4 wheels, a motor, steering wheel, etc. But machines still need to be taught to think on their own. So how can we help computers recognize patterns in a car’s digital representations? It turns out that a combination of complex algorithms and massive computing power might just do the trick.
Why would you want a machine to learn the meaning of a word and how can they do it?
Let’s start with something simple, let’s say that you have a document that is made up of only text, and you need to compare it fast with a previous version of the same document. Sure, a very simple way to do this would be if you treat words as meaningless symbols, and check if the new version of the document has the same words as the old version in the same order. In this case, the machine that is doing the comparison will consider the word “ship” totally unrelated to the word “boat.” They would be as unrelated to each other as the words “cat” and “income.” A human reader, on the other hand, would realize that the sentence “The ship was docked in the bay” has the same meaning as the sentence “The boat was docked in the bay.”
The computer’s way of treating words as “keywords” and not as something more, as just symbols, has the advantage that is fast and precise. You can search for a specific keyword in a thousand document and with 100% certainty it will tell you if the word is there or not, and where it can be found. But this method gets us nowhere when it comes to finding documents with similar meaning. Imagine you want your program to discover new documents about “taxation in Europe.” According to a keyword rule, the program might ignore documents with only the phrase “taxation in the European Union.”
So to help machines understand meaning the idea is to first replace meaning with something that machines can actually measure. What they can measure stems from the Distributional Hypothesis, which claims that “words are characterized by the company that they keep”. So having this in mind, the words “ship” and “boat” are probably representing the same notion since they collocate often with words like “sea,” “dock,” and “sail”.
There are several techniques that have been used to computationally extract meaning from a text, but in the last years the Neural Network model has become very popular. Much work on improving the learning of word representations when using Neural Networks has been done, from feed-forward networks, to hierarchical models, and recently recurrent neural networks. In this article we are only focusing on defining neural networks and how can we get from an unlabeled image to a correctly classified one.
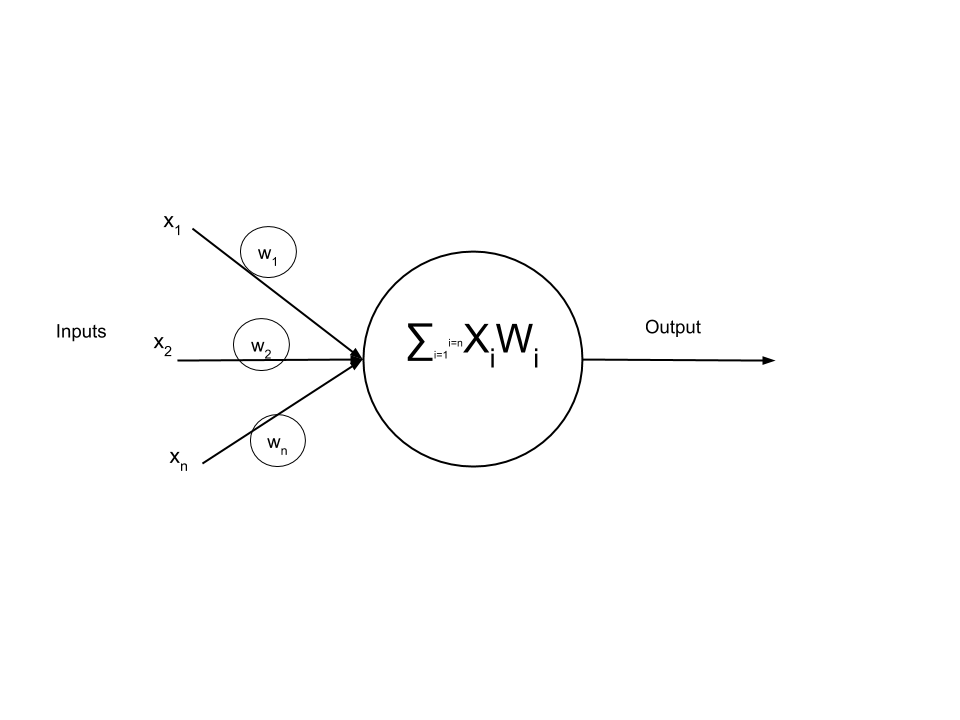
What are Neural Networks?
Neural Networks are a class of models within the general machine learning literature. They represent a set of algorithms inspired by biological neural networks and they have been proven recently to work quite well. Usually they are general function approximations, which means that they can be applied to almost any machine learning problem that needs to solve a complex mapping from the input to the output space.
So what exactly is a neural network? In the brain, different bits of the cortex do different things, and local damage to the brain has specific effects. For example, damage to a discrete part of the brain in the left frontal lobe (Broca’s area) of the language-dominant hemisphere has been shown to significantly affect the use of spontaneous speech and motor speech control. But the cortex looks pretty much the same all over, and is made of general purpose stuff that has the ability to turn into special hardware in response to experiences, yielding the biological equivalent to rapid parallel computation and redundancy. This general purpose material is your neurons.
Each neuron receives input from a network of other neurons, and few of those neurons also connect to sensory receptors. Cortical neurons use message spikes to communicate to each other. The effect of each input line on the neuron we can model with a synaptic weight, and the weights can be positive or negative. The synaptic weights adapt so that the whole network learns to perform useful computations, such as recognizing objects, understanding language, making plans, and controlling the body. You have about 1011 neurons each with about 104 weights.
An artificial neural network, on the other hand, is made up of artificial neurons. Different ways of connecting the network of neurons and selecting the weights yields vast differences in practice. We’ll use a convolutional neural network (CNN) here, a kind of multi-layer neural network designed to recognize visual patterns directly from images with minimal processing. We’ve chosen this to help us recognize handwritten numbers from the MNIST[1] dataset, as shown in Figure 2.

An artificial neuron is nothing biological. It is a function that takes input and produces output. The number of neurons that are used depends on the task at hand. It could be as few as two. Since a neuron represents a something as general as a function, it has been depicted as different things, such as the one in Figure 1. Each neuron receives input from other neurons. The effect of each input line in Figure 1 is controlled by the weight, which can be positive or negative. The neural network “learns” how to compute useful computations by adjusting those weights. If we took many more neurons similar to the one in Figure 1, we could connect them into a feed forward network. A feed forward network is a neural network in which each layer transmits their output forward to the next layer until we reach a final output. There are no loops, or going back in this kind of network. The equation describing such a network is the following:
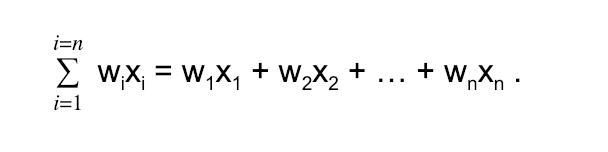
Now that we have a basic understanding of what an artificial neural network is, let’s try to use to recognize handwritten digits. The MNIST dataset is made up of images of handwritten digits, 28x28 pixels each.
The MNIST dataset comes with 60000 training images and 10000 test images. We will reserve 10000 images for cross validation. This is important because we want to be able to compare the efficiency of different methods or learning parameters that are independent of the test set.
As we said before, we can construct neural networks of any dimension and configuration. But since each image in the MNIST data set is 28x28 pixels, and each pixel represents a single input feature, being a 28x28 grayscale intensity image, the first layer of the neural network will be 28*28=784 neurons. The output layer will be 10 layers in size, one neuron for each value between 0-9. The number of intermediate layers and how many neurons they will have will be a design choice by us.
So, how would that look in Python? We will use Keras, an open source neural network library. In the following code snippet, after we do some preparations by importing some specific libraries like numpy and keras, we load the MNIST data and define the neural network and its model.
# Import Numpy, keras and MNIST data
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers.core import Dense,Dropout,Activation
from keras.utils import np_utils
# Retrieving the training and test data
(X_train,y_train),(X_test,y_test)=mnist.load_data()
print('X_train shape:',X_train.shape)
print('X_test shape: ',X_test.shape)
print('y_train shape:',y_train.shape)
print('y_test shape: ',y_test.shape)
# Defining the neural network
def build_model():
model = Sequential()
model.add(Dense(512, input_shape=(784,)))
model.add(Activation(‘relu’)) # activation is a nonlinear function applied to output
model.add(Dropout(0.2)) # the dropout is used so that the model will not overfit the data
model.add(Dense(10))
model.add(Activation(‘softmax’))
#Building the model
model=build_model()
model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])
#Training
model.fit(X_train,y_train,batch_size=128,nb_epoch=4,verbose=1,validation_data=(X_test,y_test))After building and compiling the model in Keras, we do the training, as shown at the end of the code above. Even very simple models have been shown to have a 95% accuracy, tested using the reserved testing dataset.
And that’s it! You’ve written your first neural network in Python with Keras, and you’ve trained it to recognize handwritten digits. Now you are ready to conquer the world–not really, but it’s a good start.
So, are we on the verge of a machine take-over?
Probably not. The idea that software can simulate the brain’s large array of neurons in an artificial neural network has been under development for decades, and it has led to a series of disappointments early on, with some breakthroughs in more recent years. Improvements in mathematical formulas and an increased computational power are allowing scientist to model more layers of virtual neurons. This allows them to produce advances in speech and image recognition. But just because we are able to write programs that are becoming very good at recognizing images doesn’t mean that machines are going to start an apocalypse.
General AI still has a long way to go, even though we are making great strides when it comes to solving some specific task.
Bibliography
http://yann.lecun.com/exdb/mnist/
Let me know what you think!